

Amnesiac APEs Wearing RAGs
Towards a substrate for distributed intelligence: Shared Epistemic Memory
There is a polite fiction in the agentic AI world right now: we say our agents are intelligent, when what we actually mean is they are prompted. Strip away the orchestration diagrams, the tool-calling protocols, the multi-agent debate transcripts, and you find something almost touching: a stateless function being asked to behave like a colleague with a memory.
This post is about the wardrobe we have built around that statelessness. APE here stands for Agentic Prompt Engineering: the discipline of coaxing useful behavior out of language models by chaining, routing, planning, and orchestrating their stateless calls. RAG, of course, is Retrieval-Augmented Generation: the duct tape we use to hand those calls something resembling context. Put together, much of what we are building today is amnesiac APEs wearing RAGs - stateless prompt cycles dressed in a borrowed shawl of retrieved chunks, marketed as cognition.
A note on scope: by agent here I mean any system that decides its own next action via an LLM call, whether that is a single tool-using model, a chained pipeline, or a multi-agent orchestration. The diagnosis below applies at every scale - that is part of the point.
The metaphor is not a complaint. The shawl is doing real work; RAG is one of the most quietly productive ideas in this whole space, and the field has been actively upgrading it. The problem is that we keep adding layers on top: chains, routers, planners, orchestrators, evaluators, without ever upgrading the kind of thing the agent remembers between turns. Below, I want to walk the architectural vocabulary and show that every pattern in it is already pointing at the same missing piece: a shared epistemic memory that agents read from and write to as the primary substrate of their work. That layer is exactly what the companion post on Unified Knowledge Access tries to architect; this one is the why before that how.
The patterns are fractal
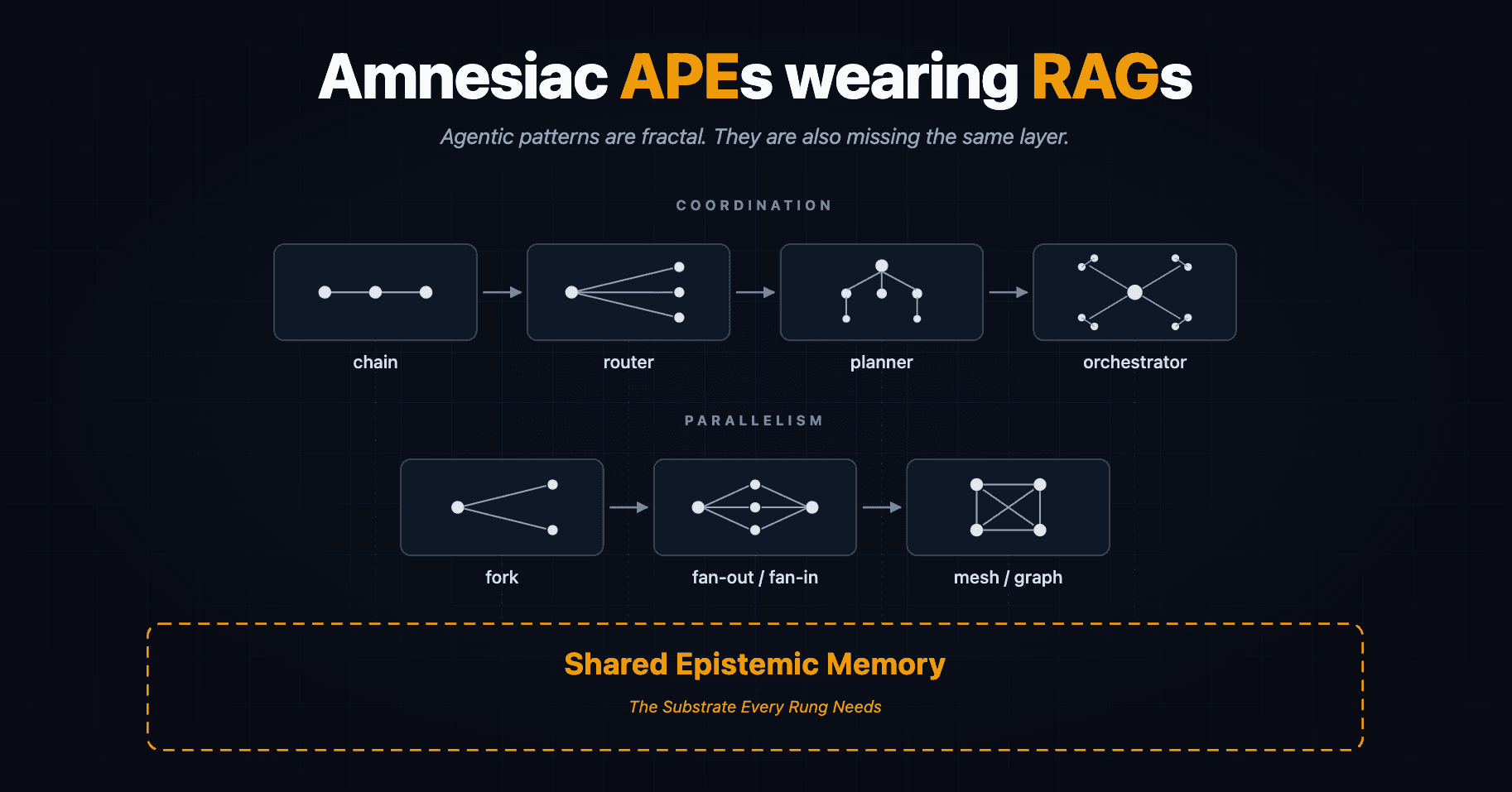
Before walking the list, the unifying observation: agentic architectural patterns are self-similar. Zoom in on a chain and you find a sequence of reasoning steps; zoom out, and the chain itself is one step in a router's decision space. Zoom out again, and the router is a node inside a planner. Zoom out further, and the planner is one role in an orchestrator's workforce.
Make the recursion explicit and the claim becomes structural rather than rhetorical. Every pattern shares a four-beat shape: receive, reason, act, hand off. A chain's "act" slot is the next LLM call. A router's "act" is selecting which chain to invoke. A planner's "act" is generating a sub-plan whose steps are themselves chains or routers. An orchestrator's "act" is delegating to a sub-agent that has its own internal planner. Each rung's act-slot can host the next rung whole. That is how production agent systems are actually composed today - and it is why the same epistemic gap shows up at every level.
This is what makes Fractal Chain of Thought useful as more than a prompting trick. FCoT applies the same reasoning operator at the brick-layer level (each step) and the architect level (the structure of the whole task). If you take the fractal claim seriously, then the pattern catalog is not a flat list. It is a ladder of zoom levels, all asking the same question of their substrate:
Chains -> Routers -> Planners -> Orchestrators
The parallelism flavor of the same fractal runs alongside it: fork generalizes to fan-out/fan-in, which generalizes to mesh and graph topologies. Same shape, more degrees of freedom at each rung.
And the question every level of either ladder asks, more sharply at each rung, is: what does this agent know, and where does that knowledge live?
Chains, routes, routers
A chain is a sequence of LLM calls where each step's output feeds the next. Useful, well-understood, and amnesiac by construction - every step's "context" is whatever the previous step happened to emit.
Routes generalize chains: instead of a fixed pipeline, a controller picks the next step from a set. Routers generalize routes: now the choice itself is learned or reasoned, often by another LLM call. The progression looks like increased flexibility, but every rung makes the memory question louder. Routing decisions need context about prior runs, success rates, observed failure modes. Today that context lives wherever the prompt engineer can stuff it - system messages, scratchpad files, state dictionaries serialized turn by turn. None of that is memory in any meaningful sense. It is a clipboard.
Fork, fan-out, mesh
The same fractal, parallelism flavor. A fork lets one branch become two; fan-out becomes fan-in; fan-in topologies generalize into meshes and graphs. The architectural elegance is real and the runtime savings are real, but the moment you have three branches reasoning concurrently you are forced to admit that they have no shared substrate to write their findings into. The orchestrator collects their outputs at the join, but anything one branch learned that another could have used is gone. The mesh makes this most embarrassing - there is no canonical trunk to bolt context onto, so you either centralize through a coordinator (defeating the mesh) or accept that branches reason past each other (defeating the parallelism).
Planners, Prioritization, Exploration, Discovery
A planner needs a world model - some internal picture of what is true, what is uncertain, what has been tried, what worked. RAG-fetched chunks do not compose into a world model. They are episodes of search, not maps of terrain. Asking a planner to function on top of a vanilla RAG pipeline is like handing an architect a stack of building photos and expecting blueprints.
Orchestrators and the protocol fallacy
Collaboration patterns - delegation, supervisor/worker, multi-agent debate - generalize into orchestrators. The current generation of agent-to-agent plumbing, including Google's A2A and Anthropic's MCP, gives us excellent infrastructure for messages but no opinion about epistemic state. The protocols ensure agent A can call agent B's tools or hand off a task; they say nothing about whether A and B share an understanding of the world the task is set in.
This is where amnesia bites the hardest. An orchestrator without shared memory is a manager whose direct reports forget their last conversation between standups. You can paper over the gap with handoff prompts and "context summaries," but you are reconstructing a shared world from scratch on every transition.
Session is not memory
Frameworks routinely conflate history, retrieval, session, state, and memory. They are not the same thing. Session is what happened during a run. State is the current position in some computation. History is the log of turns. Retrieval is a lookup against a corpus.
Memory is what has been integrated - what the agent now knows, can use, and can revise. None of the four above produce that on their own. You can persist sessions forever and still have an amnesiac agent, because nothing is doing the work of turning those sessions into something the agent reasons from rather than reasons over.
This conflation is not a vocabulary problem. It is the reason most "long-term memory" features in agent frameworks reduce to "we keep the transcript and we vector-search it later."
Data retrieval vs knowledge retrieval
The wearing RAGs jab is unfair to the most sophisticated end of the field, and worth qualifying. Modern retrieval is no longer pure vector similarity: graph RAG, hybrid retrieval, GraphRAG, and structured retrieval over knowledge graphs all exist precisely because chunk-similarity hits a ceiling. The honest framing is not RAG is wrong, but RAG is on a trajectory toward something it has not yet fully become.
Plain RAG retrieves data: chunks, embeddings, semantically nearby passages. Knowledge retrieval, what advanced graph-RAG approaches are converging towards, asks for all invoices over $10k flagged for review, or every relation in which entity X plays role Y. That kind of query needs an ontology and a query language, not a similarity score. If you have ever watched a competent vector RAG pipeline confidently retrieve the wrong document because the right one used different vocabulary, you have already seen the limit. The fix is not better embeddings; it is a substrate that knows the shape of what it stores.
Shared epistemic memory, in this light, is not the opposite of RAG. It is the destination RAG keeps trying to reach.
Guardrails: consensus, negotiation, reflection
All three of the dominant safety patterns presuppose shared ground truth. Consensus among agents is meaningless if the agents are pointing at different epistemic objects. Negotiation requires a shared world to negotiate over. Reflection without persistent memory is a goldfish examining its own life choices. The agent has nothing to reflect with, only the current turn's transcript. Each pattern is a quiet vote of no confidence in pure-RAG amnesia.
Evals, observers, red-teaming
What is the substrate being evaluated? Today we mostly evaluate traces: did the agent get to the right answer along an acceptable path? With a real epistemic substrate, you can evaluate something more interesting: what the agent believed, how that belief evolved over the run, whether the belief was warranted by the evidence available at each step. The difference between trace evals and belief-state evals is the difference between grading a student on the final exam and grading them on whether they actually learned anything during the term.
What "agent memory" already means, and what it doesn't
Before naming what is missing, it is only fair to name what exists. There is a small but growing ecosystem of attempts at giving agents memory. MemGPT (now Letta) treats the context window as a managed memory hierarchy, paging information in and out. Mem0, MemPalace, and A-MEM build per-agent fact stores with retrieval over them. LangGraph's checkpointers persist execution state across runs. Park et al.'s Generative Agents introduced reflection-based memory consolidation and inspired a wave of follow-ups. Commercial offerings like Zep ship episodic and semantic stores out of the box.
These are real progress. What they share, however, is a particular shape: each agent has its own memory, written in its own schema, retrieved through its own mechanism. They solve the temporal problem i.e. one agent remembering across its own sessions without solving the structural one, in which two agents need to remember in mutually intelligible formats. They are, almost without exception, single-agent memory systems wearing multi-agent costumes.
That gap is what the rest of this post is about.
Shared epistemic memory
A shared epistemic memory is a living knowledge network that agents primarily read from and write to as opposed to a vector store, a transcript log, or a session blob. A structured substrate where multiple agents, across runs, across instances, possibly across organizations, accumulate, abstract, and revise what they collectively know.
The word shared in this phrase does double duty deliberately. It is temporally shared. One agent's knowledge survives sessions and accumulates into a stable belief state, instead of being reconstructed from scratch each turn. It is also spatially shared. Multiple agents, possibly heterogeneous and possibly never co-located, can read and write the same substrate without losing meaning in translation. The strongest version of the thesis is that the same schema-grounded structure solves both. Most existing memory systems solve only the first.
To head off a concern that follows naturally from a phrase like shared memory: "shared" here is structural, not topological. It means agents agree on the shape of what they store, not that they all write to one server. The architecture in the companion post makes this explicit - the substrate can be local, peer-to-peer, or federated, with edge replicas and content-addressed identity. For now, take "shared" to mean "interoperable."
Three layers of memory show up cleanly when you look at how agents actually need to remember things. The taxonomy is roughly the Tulving / Squire split, repurposed:
Erfahrung (episodic). German, because English flattens the distinction. Erlebnis is mere lived-through experience - a moment that happened. Erfahrung, in the Gadamerian sense, is experience that has been integrated into the experiencer's understanding; experience that changes the experiencer. Episodic memory in agents should aim at Erfahrung, not just Erlebnis. Architecturally the difference is concrete: an Erfahrung-shaped write does not just append the event, it pairs the event with a delta to the agent's belief state - what changed, in which schema, and why. The episodic layer becomes a record of belief revision, not just occurrence.
Semantic memory. The abstracted, generalized facts and relations distilled from many episodes. The "living knowledge network" in the literal sense - graph-shaped, queryable, revisable. This is the layer that should grow more useful over time as agents contribute observations to it.
Procedural memory. Skills, learned behaviors, role-conditioned competencies. In ontology terms - and TypeDB makes this elegant - this is where the EAR primitives (Entity / Attribute / Relationship) and the additional notion of Roles come in. Entities don't merely exist; they play roles in relationships, and an agent's procedural memory is, in part, knowledge of which roles it can occupy and what those roles entail.
A shared epistemic memory layer needs all three, written in a form that other agents - including agents the original author never met - can read meaningfully.
Why a meta-schema is non-negotiable
This is the part that a stateful database alone cannot solve. Even if every agent writes faithfully to a shared store, they will write in their own schemas unless something forces structural agreement. A schema-per-agent network is just a federated mess wearing nicer clothes than RAG.
What is needed is a meta-schema: an agreement about the shape of schemas, not just the schemas themselves. TypeDB's evolution is instructive here. The old Thing | ThingType distinction has matured into a richer hierarchy in which Concept is the supertype of EntityType, RelationType, RoleType, AttributeType and their instances Entity, Relation, Attribute. That hierarchy is a meta-schema - a small, stable vocabulary for talking about what kinds of things schemas are allowed to contain.
In Part 1 of this series I called the corresponding mnemonic MACER - Metatype, Archetype, Concept, Entity, Relation - and argued that this layered ontology is how a decentralized system maintains coherence even when local datasets diverge. Two edge agents may know completely different Entities, but if they share Metatypes and Archetypes they can still talk to each other about the same kinds of things. That property of semantic interoperability with structural divergence is exactly what a multi-agent system needs to make its shared epistemic memory more than a free-for-all.
What this costs
None of this is cheap. Building a shared epistemic substrate even within a single team's agent fleet, let alone across organizations, drags in every problem that has tormented knowledge engineering for forty years. Schema agreement is hard. Governance of who gets to write what kind of fact, and who arbitrates contradictions, is harder. Cold-start (the first agents on a new substrate have nothing to read) is a real friction. Belief drift, stale facts, hostile writes, and the privacy implications of agents pooling observations are all live problems, not solved ones.
The argument here is not that this is easy. The argument is that the alternative with no such layer, every agentic pattern paying the cost of amnesia at every rung of the fractal is more expensive over time, and pays its costs in less visible ways. Brittle handoffs, contradictory parallel branches, evals that grade the wrong thing, safety patterns that presuppose ground truth that does not exist.
Handing off to the implementation
If the diagnosis here is right, the architectural question is no longer whether to build a shared epistemic substrate but how. The diagnosis itself sets the requirements: a meta-schema agents agree on (so writes from heterogeneous sources stay intelligible); content-addressed identity for shared concepts (so agents pass references instead of payloads, and de-duplicate naturally); intensional logic alongside extensional facts (so the substrate carries rules, not just rows); and topological flexibility - local, peer-to-peer, or federated, so "shared" never collapses into "centralized."
Those four requirements pick out a specific stack, which I sketched in Unified Knowledge Access & Distributed Intelligence: MACER as the meta-schema, TypeDB as the logic layer carrying both extensional facts and intensional Horn clauses, CIDs as the addressing primitive that lets agents pass references rather than payloads, and a local-first plus cloud orchestration model that lets edge agents reason with full ontological context even when partitioned from the network.
This post is the why. That post is the how. Together they sketch a future in which agents stop being amnesiacs improvising in borrowed shawls, and start being participants in a shared, structured, living knowledge network - agents who remember and share memories, across time and across various instances and reincarnations.
The rag as a shawl is comfortable. It is also, if we are honest with ourselves, just a minimal cover that works for now.
We will be needing something better for the winter.



