Anarchitecture & Skunkworks
A road map for research & development in the area of enterprise collaboration architecture, unified research & sharing of intellectual digital assets

This article describes the road map for research & development in the area of enterprise collaboration architecture, unified research and sharing of intellectual and digital assets. We then describe how this enables nep.work to operate a Skunkworks-like cross-organizational framework for radical innovations not otherwise possible within the confines of organizational silos.
Introduction
Multiple pioneering players in industry are working on overlapping interests. While competition between individual companies is the key to driving innovation in a free market, it is not particularly optimal for the market as a whole because it involves significant duplication of similar efforts and investments. Redundancies within the systems of production especially in a resource constrained nation like ours can be reduced by our proposed model of forming large collaborations and fostering competitions between collaborating groups as opposed to that between individual companies. This way companies can also level the playing field when it comes to the more concerning competition with large foreign business entities.
Skunkworks is a corporate practice that originated 77 years ago as a radical approach for quick delivery of better products than the competition. In Lockheed Martin's eponymous case, the end product was a fighter jet expected to fly 200 miles per hour faster than the best in competition - high-speed German fighter jets, which were literal threats - but to be completed in just 180 days. This originally utilized an isolation-based approach to enable radically innovative work. In its current form, it still bypasses bureaucracy via selective isolation but it judiciously crosses departments and even organizations especially when given the right tools and protocols. Ideally companies should be continuously innovating and not needing a dedicated Skunkworks team. However, we need to initially resolve the problem that low capital companies can only do incremental innovations despite much needed large-scale breakthroughs for the overall market, owing to a less literal but devastating threat from multinationals and powerful foreign players.
Mass adoption of some of these enterprise technologies, both prospective or already developed, imply a tectonic shift in industry. Although these are not moonshot projects, these are still significantly challenging for most companies to carry out on their own. To this end, we have selectively consolidated parallel research and development efforts in multiple partnering companies to create a unified front that encompasses key areas of high interest to the business community. These projects will be open sourced under the stewardship of NAAMII's I & I committee, which will also include various pioneering business leaders, and will have representations from the overall business community via a community process with an open RFC driven decision making. The main focus is on collaboratively solving the industry's present problems with the most significant returns on investment or impact on business workflow optimization.
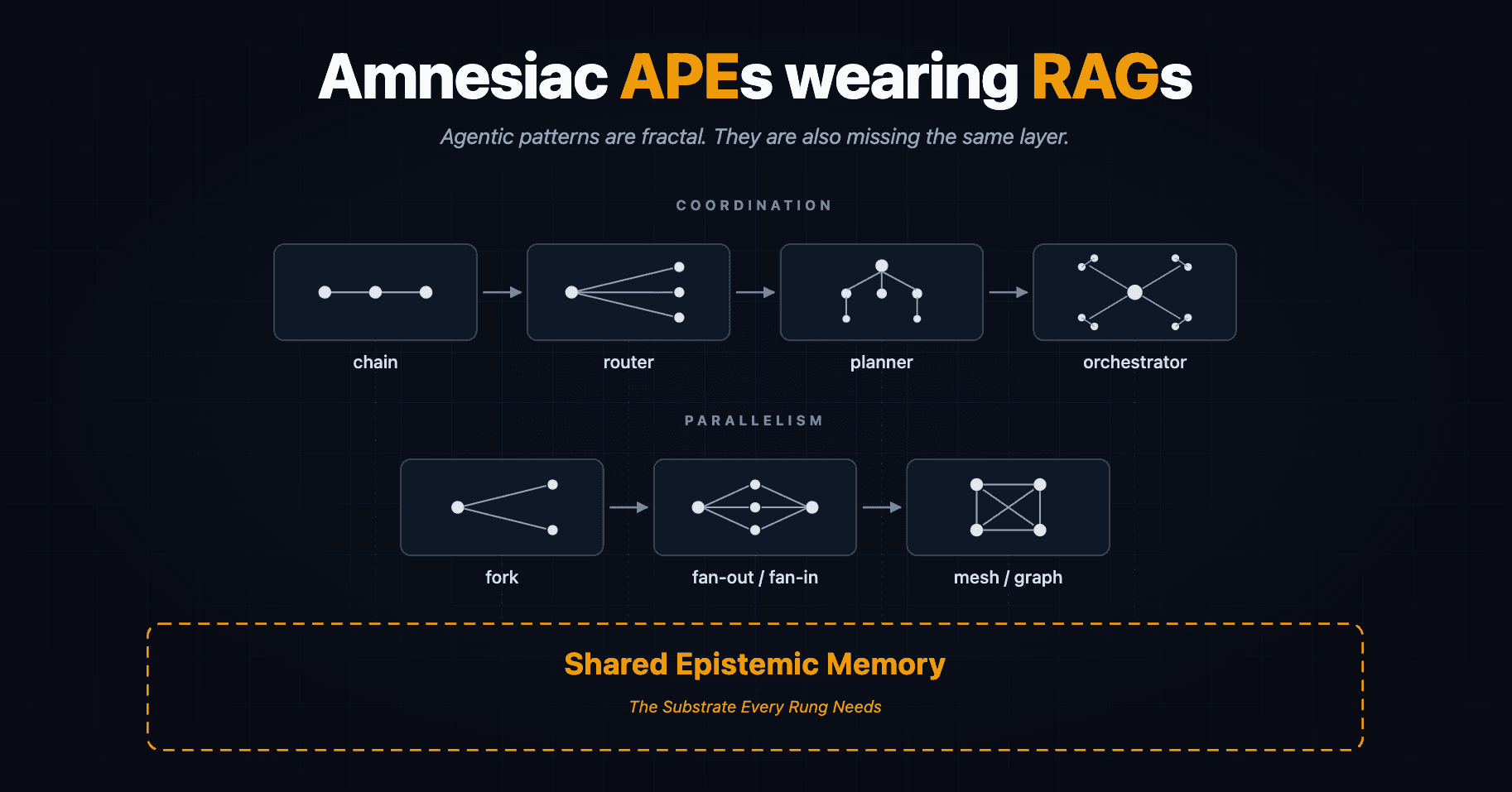
Concepts, Ontologies & Network Variants
Businesses and business processes have an inherent redundancy and re-actions involved. To do more than what we are doing now, we need to automate what we are doing now. To automate processes, we should start with annotating processes. We need to identify processes and connect them as needed. Each of the nodes in such a system is essentially model-able as a node in a social-political hyper-graph. Some of the nodes may be an individual. Since these nodes are admitted in a type agnostic way, any kind of node may exist. Some nodes may just be friendship's graph friends or some may be just representation of business workflow for writing, editing, approval, signing, sending, receiving, acknowledging and responding documents. These documents can form companies, organizations, projects, business deals and execution project's team playground.
What to Not Do
Since we are dealing with broad topics and scopes, we need to focus the efforts and scopes especially when getting started. In doing so, we also need to see what needs to be done first and what else can be done along with it. We propose starting simply with the beginning - entities and identities in a CoSys knowledge base (KB) or database (DB).
Where to Begin
We begin and end this document with the matrix. This was written around 2012-13 and has been the effective outline till the next decade.
Identity
An identity is a key with which the credential server returns the entity itself.
Entity
Any construct or structure in our DB or KB that has an identity is called an entity.
ID-IP
Identity that is e2e and p2p connected to identity's IP (intellectual property).
Codes
Code can be 1 dimensional in case of numbers or non-nested arrays.
Algebras
Codes have tuples of inputs which form algebraic structures and algebras.
Sciences
Code libraries of academic contexts and custom constants and constraints.
Environment
Code integrations form end to end systems in a given Environment.
PI-ID
Property IDs that are e2e and p2p connected to identity's IP and contexts.
Q Queries
Code query params can are always part of a unit dimensional array.
I Space
Codes' IDs are in a tuple space with custom algebraic structures and algebras.
J Resource
Codes live within distinct resources of academic contexts and constraints.
K Environment
Code integrations form end to end systems in a given environment.
Are there things that have no identities? What can we do about those that do? What should we not do? Simply put we do not do anything other than GET, PUT, POST and OPTIONS.